前言
近几年,微博快速成长为国内最大的社交平台之一,月活跃用户已近4亿。不同于微信、QQ等社交平台,微博是一个着重于分享简短实时信息的广播式的社交平台,并且每个人的所发布的信息都是公开化的,所有用户都可以阅读、评论、转发。依托于微博这一性质,微博也为我们提供了一个集新闻咨询、娱乐八卦等各种信息为一体的大数据平台。但仅靠我们平时翻阅只能接触到微不足道的一小部分信息,正因为如此,便有了网络爬虫这门技术,依靠编程语言实现大批量数据的爬取保存。最后,我们可以利用这些大数据信息进行数据处理、分析以得到我们想要的信息。
对于微博爬虫,我们可以爬取到多样的数据,比如热门微博的内容和评论、某微博用户的所有微博内容、某地区的微博内容等等。今天我要爬取的是某一地区近段时间的微博内容,爬取到的内容主要包括微博用户名、微博发布日期、微博发布的定位地址、手机类型以及微博详细内容。利用这些信息我们大致可以分析出这一地区的微博使用人群的发微博的主要时间段、使用的手机类别,甚至于通过这些信息去寻找我们要找的人。
准备工作
- 安装好python环境
- 安装对应的python库。(我这里主要用到了beautifulsoup、pandas、re、requests)
正式开始
对于爬虫来说手机端的网页我们作为首选,因为手机端的页面往往结构更简单,爬取难度较小。但是与电脑端的网页相比,手机端的页面上内容更少,有时候根本没有我们需要的数据。因此,这里我选择了爬取电脑端的微博页面内容。
一、分析网页结构
在浏览器进到我们需要爬取的网页中,查看网页源码,查看是否包含自己需要的全部内容。由于现在的网站页面都已经是动态加载的了,纯静态网页已经很少了,所以往往我们直接访问的链接中不完全包含我们需要的内容、甚至于没有我们需要的内容,但是浏览器显示上又存在这些内容,这是怎么回事呢?这就涉及到了ajax这些动态网页技术了,这里我们不作深究。对于这种情况我们可以在浏览器的高级工具中找到这些实时加载的链接。
往往我们爬取的内容都还存在翻页的情况,不同的页码下链接也会有细微的差别,这就需要我们视情况分析了。下面两个链接就是我这次爬虫所涉及到的两个主要链接,不同的页码数只需改变其中的个别变量。
https://weibo.com/p/1001018008651010513000000?current_page=9&since_id=&page=%s
https://weibo.com/p/aj/v6/mblog/mbloglist?ajwvr=6&domain=100101¤t_page=%s&since_id=&page=%s&pagebar=%s&tab=home&pl_name=Pl_Third_App__17&id=1001018008651010513000000&script_uri=/p/1001018008651010513000000&feed_type=1&pre_page=%s&domain_op=100101
二、调试代码
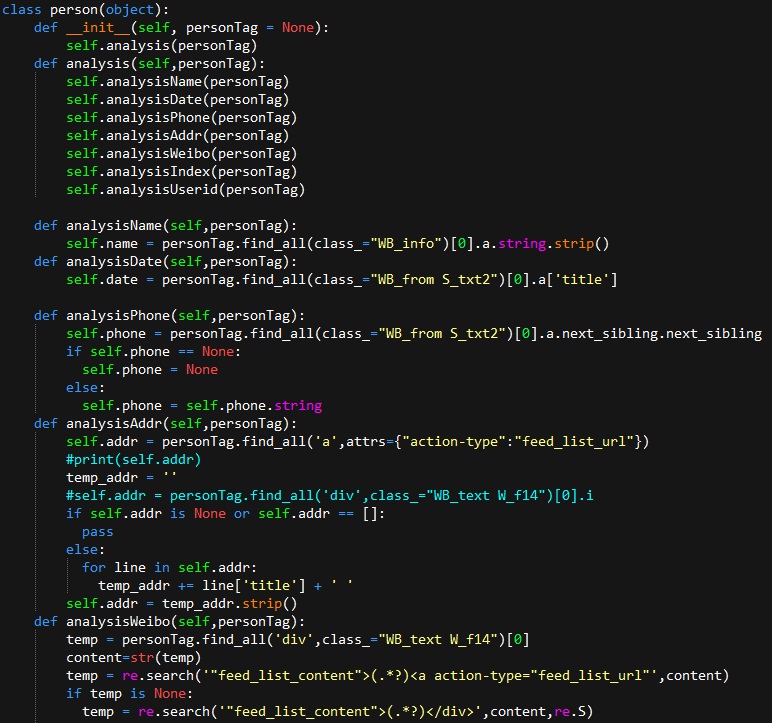
接下来要做的就是根据之前对网页结构的分析开始编写、调试代码。我这里主要用到的是beautifulsoup和re对页面中需要的内容进行提取。
部分代码:
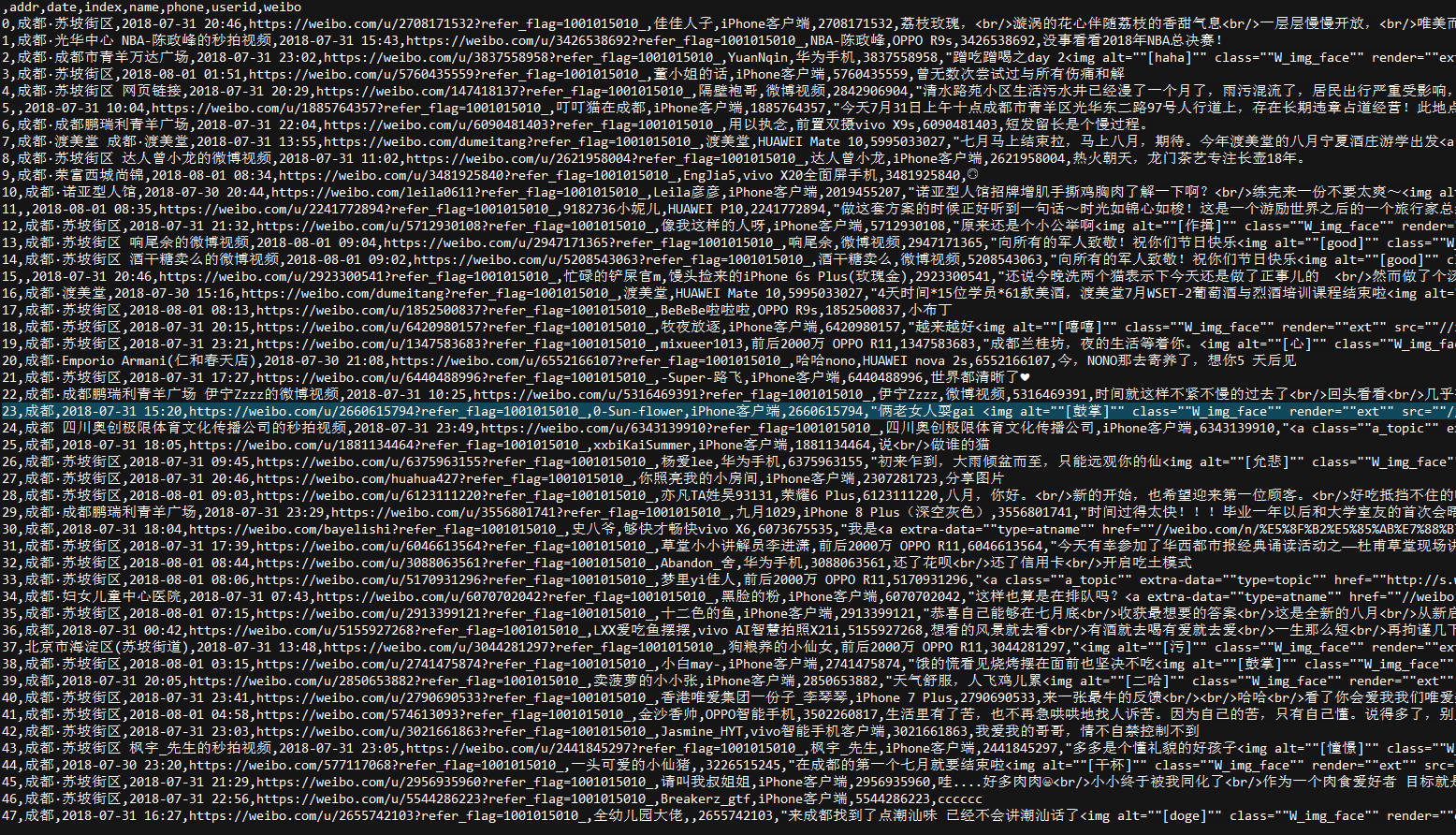
爬取到的内容(部分):
三、数据清洗
整理数据,比如清除掉无效数据、重复数据等等。视具体情况具体分析。
四、数据分析
根据具体需求具体分析。前面我总共爬到1000+条微博数据。在这里我利用爬取到的用户ID,再一次爬取这些微博用户与我共同关注的微博博主。
部分代码:
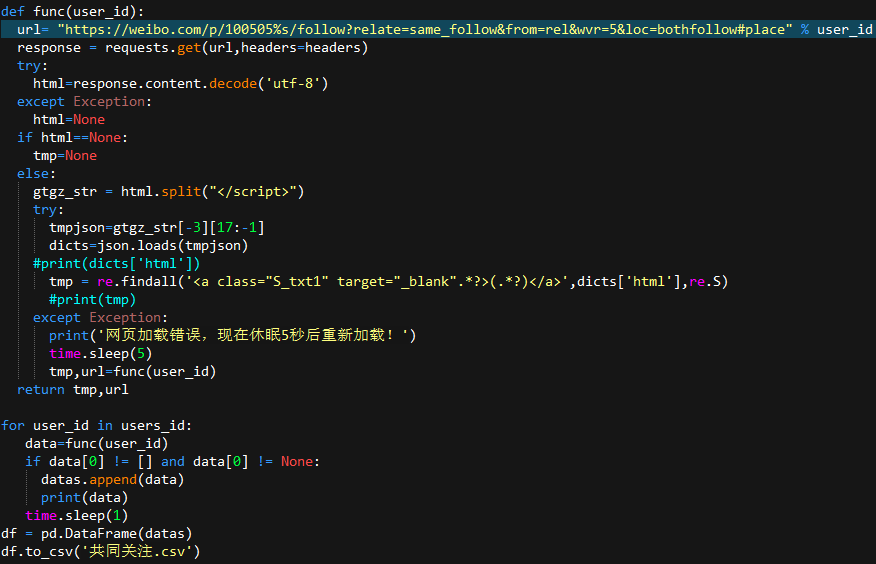
最终需要的结果: